Il est devenu courant d’entendre de nos jours des propos sur « l’effondrement de LA société industrielle ». Mais c’est sans doute trop simpliste. Nous soutiendrons dans cet article que, en certains lieux, le capital informationnel qui caractérise cette civilisation (techniques, procédés, savoir-faire, organisations… ) continuera d’augmenter, ainsi que la résilience au réchauffement climatique et à la déplétion des ressources.
Nous partirons de la définition de l’effondrement de Joseph Tainter, un des pionniers de l’approche scientifique de cette notion. Elle tient en 3 points : 1/ Plus une société est complexe, plus elle requiert de l’énergie ; 2/ Après avoir épuisé l’énergie bon marché et la dette abordable, elle perd sa capacité à résoudre ses problèmes ; 3/ L’effondrement est la simplification rapide d’une société.
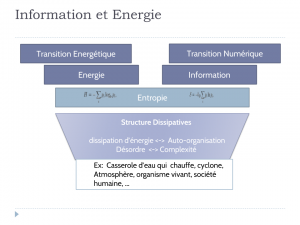
Cette définition lie l’effondrement à la notion de complexité, et celle-ci aux flux énergétiques. C’est un lien qu’étudie aussi la thermodynamique, en particulier à partir des travaux de Igor Prigogine sur les structures dissipatives : ce sont des structures qui reçoivent un flux énergétique de l’extérieur, mais qui créent des formes d’organisation à l’intérieur via importation et mémorisation de l’information. L’eau qui bout dans une casserole est l’image classique d’une telle structure, mais c’est aussi valable pour les cellules qui mémorisent l’information dans l’ADN, et pour les sociétés humaines qui la mémorisent via la transmission culturelle.
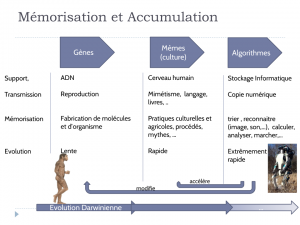
Ainsi l’évolution biologique se traduit par une augmentation de la complexité (des organismes eucaryotes aux animaux), qui a pour support une information stockée dans les gènes sous forme d’ADN. Selon la théorie darwinienne, les gènes se répliquent, évoluent par altérations et fusions, et transmettent les changements favorables à leur descendant. Ils augmentent ce faisant leur capacité à se perpétuer et à s’adapter à l’environnement, c’est-à-dire à ‘résoudre les problèmes’ selon les termes de Tainter.
L’évolution de la culture humaine est similaire. Les pratiques agricoles par exemple se transmettent de génération d’agriculteurs à la suivante, via le langage, l’imitation, les livres ou, plus récemment, Internet. Elles peuvent évoluer par le hasard ou l’adaptation de pratiques développées par ailleurs. Les pratiques les plus efficaces augmentent la résilience des sociétés qui les adoptent, ce qui renforce leur diffusion. Il en est de même pour les pratiques militaires, les savoir-faire pour fabriquer des objets, les capacités à échanger ou à organiser une société en croissance démographique, etc.
Ces évolutions peuvent être considérées comme l’évolution d’algorithmes. Une recette culinaire est l’exemple typique d’un algorithme, et nous pouvons aussi considérer les pratiques agricoles, militaires ou de fabrication d’objets comme des algorithmes. Nous les appellerons ‘algorithmes culturels”. Les gènes peuvent aussi être considérés comme des algorithmes, que nous qualifierons de ‘biologiques”. Ils permettent la fabrication pas-à-pas de protéines et d’organismes selon un programme codé dans l’ADN. Les comportements des animaux, comme la sélection du partenaire pour assurer la reproduction, ou les choix à prendre face à un prédateur, sont aussi des algorithmes biologiques susceptibles de s’améliorer de génération en génération.
La révolution que nous vivons est liée à l’apparition d’une nouvelle forme d’algorithmes : les algorithmes numériques. Ceux-ci évoluent par des mécanismes similaires à ceux décrits précédemment : il y a un processus de génération de variantes, puis de sélection des celles qui apportent un avantage, et finalement transmission à une nouvelle génération. Par exemple, des dizaines de milliers d’informaticiens modifient tous les jours des algorithmes numériques disponibles en open source. Une de ces modifications pourrait avoir un intérêt pour améliorer une fonctionnalité du noyau Linux, être sélectionnée et intégrée dans le noyau, et se retrouver quelques années plus tard dans des millions de smartphones et d’ordinateurs.
Le processus de création et d’amélioration des algorithmes numériques est en train de s’accélérer. Plusieurs processus sont en cours : d’une part, le « big data » et l’apprentissage automatique permettent de créer des algorithmes à partir de très grands volumes de données. C’est ainsi qu’un ordinateur peut faire un algorithme pour reconnaître un objet si on lui a fourni au préalable des centaines d’images de cet objet. C’est la technique de base de l’intelligence artificielle (IA). Mais d’autres techniques plus puissantes apparaissent, où des algorithmes créent d’autres algorithmes avec peu de données. Par exemple, le programme de jeu de Go développé par Google, qui a gagné contre le champion du monde, a d’abord été entraîné à évaluer des positions à partir d’un catalogue d’un million de parties jouées par des humains. Puis, une nouvelle version a appris à évaluer la position seulement en jouant des milliers de parties contre elle-même. Le processus s’apparente d’ailleurs à l’évolution biologique : après chaque jeu, quelques changements sont introduits dans la version qui a gagné pour produire d’autres versions, qui jouent les unes contre les autres, etc.
Un autre processus d’accélération est la concentration des données et des algorithmes dans les grandes plateformes numériques, telles que celles détenues par Amazon, Microsoft, Google ou Alibaba, qui proposent des services facilitant la composition de milliers d’algorithmes qu’elles mettent à disposition. Ces services sont utilisés par ces entreprises pour leurs besoins propres, mais aussi par d’autres entreprises, notamment les startups pour développer de nouvelles idées à moindre coût. Ces startups, à leur tour, peuvent mettre en open source leurs propres variantes, qui pourront éventuellement être intégrées à ces plateformes. Elles peuvent aussi développer leur propre plateforme (comme Uber, AirBnB,..), essentiellement pour fournir des services qui vont servir à collecter des données, et alimenter ainsi la création d’algorithmes par des techniques d’apprentissage automatique. Les plateformes numériques servent ainsi de catalyseurs : en mettant à proximité données et algorithmes, et en facilitant la modification et combinaison des algorithmes ainsi que la création de ceux-ci par apprentissage, elles accélèrent le processus de création et d’amélioration des algorithmes numériques. C’est cette amélioration exponentielle des algorithmes numériques qui explique qu’ils sont en train de remplacer algorithmes biologiques et culturels pour de plus en plus de tâches.
Tous les pays industrialisés luttent maintenant pour développer et contrôler les algorithmes d’IA, car ils sont une partie essentielle de leur souveraineté et de leur indépendance. Le contrôle du processus d’innovation et des plates-formes deviennent d’une importance capitale, et la Chine et les gouvernements américains ont pris un avantage certain. Ils l’ont obtenu via les agences de recherche militaires, comme le DARPA aux USA, qui investissent massivement, et souvent en cofinancement avec les grands fournisseurs de plates-formes commerciales. En résulte un flux de nouvelles idées et d’algorithmes, qui sont sélectionnés d’une manière ou d’une autre. Ceux qui apportent un avantage sont incorporés dans ces plateformes pour les usages commerciaux, mais peuvent également être utilisés par les États pour contrôler l’information et améliorer leur défense (comme les armes basées sur l’IA, les systèmes de renseignement, etc).
Revenons maintenant à l’effondrement. Notre analyse est qu’une nouvelle forme de structure dissipative est en train d’émerger, essentiellement aux USA et en Chine, où s’accumulent des algorithmes numériques qui leur permettent une meilleure connaissance de l’environnement, et des capacités accrues d’agir sur lui. C’est un peu comme l’évolution biologique et culturelle, mais ici l’environnement est perçu grâce à des algorithmes qui surveillent l’Internet, contrôlent et analysent des images de satellites, drones ou les caméras dans les rues, etc. L’action sur l’environnement se fait via d’autres algorithmes au coeur de système d’armes sophistiquées, de robots (pour fabriquer des objets, combattre, lutter dans la cybersphère…), ou d’autres algorithmes permettant la propagande de masse.
Grâce à ces algorithmes, les structures dissipatives pourront s’approprier les ressources naturelles (énergie et matière première) nécessaires à leur adaptation à un monde où ces ressources deviendront de plus en plus rares. Par ailleurs, les algorithmes numériques pourront aussi modifier directement les algorithmes biologiques codés dans l’ADN via les techniques de modification génériques comme CRISPR, pour notamment accélérer l’adaptation des plantes au réchauffement climatique. Avec les outils de propagandes et de contrôle de l’information, il sera possible de contrôler les populations et, associé à quelques contraintes, l’amener à s’adapter plus vite aux changements à venir. Ce sera d’autant plus facile que les robots et le remplacement grandissant des emplois humains par des algorithmes affaiblissent la plupart des classes sociales, limitant leur capacité de réaction par la grève. Les algorithmes augmenteront aussi la résilience des sociétés en facilitant la transmission du savoir par Internet, la mise en place de systèmes de rationnements, la création de monnaies locale, l’optimisation des déplacements et flux d’énergie.
Reprenons l’exemple de la Chine pour illustrer nos propos. Le réchauffement climatique et la déplétion des ressources fossiles pourraient y provoquer de gigantesques famines, de très fortes tensions sociales, un effondrement financier, économique et politique, etc. Mais le Parti communiste chinois (PCC), dernier avatar d’un système politique commencé il y a 2200 ans, n’est pas inactif. Il investit massivement dans la recherche en IA et toute la chaîne en amont de traitement de l’information, depuis les métaux rares pour fabriquer les puces électroniques jusqu’à l’infrastructure internet, ce qui lui permet de construire des systèmes de propagandes et de contrôles de la population jamais vue dans l’histoire, et bientôt d’avoir tous les économiques contrôlés et optimisés par de l’IA. Il développe la puissance militaire et une stratégie pour contrôler l’accès aux matières premières qui manquent, en particulier alimentaires. Il fait étudier toutes les sortes de centrales nucléaires à surgénération, ce qui, en complément des énergies renouvelables, des smart-grids et du charbon, devrait atténuer les conséquences du pic de production de pétrole, notamment via l’électrification des transports. Tout cela, et bien d’autres éléments, laissent à penser que le PCC se prépare à un effondrement, et accumule des moyens de ‘résoudre les problèmes’ – pour reprendre l’analyse de Tainter – même avec moins d’énergie et de ressources naturelles. Les algorithmes et les biotechnologies seront cruciaux, pour toutes les raisons que nous avons présentées, ce qui nécessite et justifie la continuation d’une société industrielle, au service d’une minorité.
Nous avons donc 2 phénomènes concomitants. Dans certains endroits de la planète, l’accumulation d’information algorithmique permet une augmentation de la complexité qui augment fortement les capacités d’adaptation à un environnement en rapide changement, notamment grâce à l’IA et les biotechnologies. Les armées auront un rôle essentiel, car elles sont capables d’accaparer les ressources, maintenir la complexité d’une société même en cas de crise, focaliser la recherche, construire des infrastructures, réduire la concurrence etc.
Mais partout ailleurs, le réchauffement climatique, la déplétion des ressources et le pillage de celles restantes entraîneront effondrement, guerres et famines,réduction de la population et de la complexité et la capacité de s’adapter. L’empreinte écologique globale se réduira fortement, ce qui éloignera la Terre des seuils – notamment climatiques – susceptible de la rendre quasiment inhabitable pour l’homme.
Nous avons montré que le développement des algorithmes s’accélère, et ça devrait continuer en nécessitant de moins en moins de données et d’énergie. Les processus d’effondrement vont aussi s’accélérer, car ils impliquent des boucles de rétroaction positives comme le montrent toutes les études de collapsologie. Ces 2 évolutions de nature exponentielles s’opposent, et il est impossible de prévoir comment elles vont s’imbriquer. On peut toutefois imaginer qu’une situation assez stable émerge, dans laquelle continueraient à se développer des sociétés complexes, très technologiques, efficaces en matières premières, probablement impérialistes, peu nombreuses et relativement peu peuplées. Un futur hélas pas réjouissant pour la grande majorité des autres habitants de la planète, et notamment sans doute pour nous, Européens.
Nous vivons une révolution technologique, amenée par des systèmes basés sur des techniques d’Intelligence Artificielle (IA) qui sont sur le point de faire aussi bien que les humains pour une large gamme d’activités, telles que conduire une voiture, répondre aux demandes des clients, recommander un livre, ou diagnostiquer des maladies. Ces systèmes sont constitués de centaines de milliers d’algorithmes informatiques enchevêtrés, qui évoluent rapidement, tellement rapidement que cela suscite de nombreuses inquiétudes quant aux impacts sur les sociétés humaines. Mais quelles sont les lois qui régissent ces évolutions ?
Dans cet article, nous proposons une réponse provocante à cette question : nous suggérons que les lois darwiniennes, qui régissent l’évolution biologique et culturelle, régissent aussi l’évolution des algorithmes informatiques. Les mêmes mécanismes sont à l’œuvre pour créer de la complexité, des cellules aux humains, des humains aux robots.
Plus précisément, nous nous concentrerons sur la théorie du Darwinisme Universel, une version généralisée des mécanismes de variation, de sélection et d’hérédité proposés par Charles Darwin, déjà appliquée pour expliquer l’évolution dans une grande variété d’autres domaines, comme l’anthropologie, la musique, la culture ou la cosmologie. Selon cette approche, de nombreux processus évolutifs peuvent être décomposés en trois composantes : 1/ Variation d’une forme ou d’un modèle donné, typiquement par mutation ou recombinaison ; 2/ Sélection des variantes les plus adaptées ; 3/ Hérédité ou rétention, permettant de conserver et transmettre ces variations.
Nous commencerons par donner des exemples simples, pour illustrer comment ce mécanisme s’intègre bien dans l’évolution des algorithmes « open source ». Cela nous amènera à considérer les grandes plateformes numériques comme des organismes, où les algorithmes sont sélectionnés et transmis. Ces plateformes ont un rôle important dans l’émergence des techniques d’apprentissage automatique, et nous étudierons cette évolution du point de vue darwiniste dans la section 2. Dans la troisième section, nous élargirons notre champ d’action et nous ferons nôtre la vision selon laquelle les gènes et certains éléments de la culture peuvent être considérés comme des algorithmes, de même que la concurrence pour les emplois entre l’homme et les machines peut être assimilée à un processus darwinien, mû par le passage des algorithmes humains aux algorithmes numériques. Dans la dernière section, nous étudierons plus en détail certaines des boucles de rétroaction qui sous-tendent l’évolution des algorithmes biologiques, culturels et numériques. Ces boucles de rétroaction aident à comprendre la fantastique rapidité d’évolution des algorithmes que nous voyons de nos jours, et mènent à des aperçus troublants sur le transhumanisme et les conséquences potentielles de l’IA dans nos sociétés.
1 – L’Évolution Darwinienne des Algorithmes Informatiques
Commençons par un exemple. De nombreux chercheurs et entreprises travaillent à l’amélioration du noyau du système d’exploitation open source ‘Linux’. Qu’ils travaillent sur de nouveaux concepts, ou sur une légère amélioration des algorithmes, le processus allant d’une idée d’amélioration au changement introduit dans la version principale du noyau (le ‘tronc’) est long, et beaucoup d’idées ou de propositions n’auront pas de suites. Mais si une modification est acceptée, alors le changement sera conservé pendant longtemps dans la base de code Linux. Elle servira de référence pour les travaux futurs, et pourrait être à un moment donné déployé sur des millions d’ordinateurs sous Linux, des smartphones aux supercalculateurs.
Nous voyons que la description du darwinisme universel ci-dessus est valable pour notre exemple: 1/ Des variantes des nombreux algorithmes Linux sont continuellement créées, typiquement en changeant une partie d’un algorithme existant ou en combinant différents algorithmes (souvent développés dans un autre contexte) 2/ Les meilleures variations apportant un bénéfice sont sélectionnées, et mises dans une version du noyau Linux 3/ Cette version du noyau est intégrée dans des milliers de produits, et deviennent la base de nouvelles évolutions. Tout comme les gènes survivent et continuent d’évoluer après la mort des cellules, les algorithmes de votre smartphone continuent d’évoluer après que vous ayez décidé de la changer pour un nouveau avec des algorithmes améliorés ou plus de fonctionnalités.
Plus généralement, tout le mouvement open-source suit ce processus évolutif. Sur Github par exemple – la plus grande plate-forme de développement open-source, des millions de projets existent et sont continuellement copiés, modifiés et recombinés par des millions de développeurs de logiciels. Certains changements sont sélectionnés pour être introduits dans la ligne principale d’un produit et deviennent stables et susceptibles d’être réutilisés dans de nombreux projets, tandis que la plupart d’entre eux sont oubliés. L’analogie avec l’évolution des gènes est forte : le contenu génétique des organismes mute et se recombine avec d’autres continuellement, et, parfois, des changements apportent un avantage et sont conservés dans de longues lignées de descendants.
Les codes des projets open-sources les plus intéressants sont intégrés en combiné dans de grandes plateformes de Cloud Computing, comme celle détenue par Amazon (Amazon Web Services) ou ses concurrents tels que Microsoft, Google ou Alibaba, qui proposent des services facilitant la composition de milliers d’algorithmes qu’elles mettent à disposition. Ces services sont utilisés par ces entreprises pour leurs besoins propres, mais aussi par d’autres entreprises, notamment les startups pour développer de nouvelles idées à moindre coût. Ces startups, à leur tour, peuvent mettre en open-source leurs propres variantes, qui pourront éventuellement être intégrées à ces plateformes. Ces plateformes servent ainsi de catalyseurs : elles font appliquer le processus évolutif darwiniste décrit ci-dessus en accélérant la combinaison, la sélection et la rétention des algorithmes.
2 – Évolution darwiniste des algorithmes de l’IA
Les services fournis par ces plateformes permettent de collecter beaucoup de données, ce qui conduit également à une percée majeure dans la dynamique d’évolution des algorithmes. En effet, les techniques d’apprentissage automatique permettent de créer des algorithmes à partir de données. Historiquement, la plupart des algorithmes ont été créés méticuleusement par les humains. Mais de nos jours, les systèmes d’apprentissage automatique utilisent des méta-algorithmes (par exemple, les réseaux de neurones artificiels) pour créer de nouveaux algorithmes. Ces algorithmes peuvent être appelés ‘modèles’ ou ‘agents’. Ils sont généralement créés en étant alimentés par de très grands ensembles de données d’exemples (« Big Data ») mais pas seulement.
Les progrès des algorithmes pour jouer au jeu de Go illustrent cette évolution. Pendant des décennies, les programmeurs ont développé et amélioré manuellement des algorithmes pour évaluer les positions et les mouvements du jeu. Mais de nos jours, les meilleurs logiciels utilisent des techniques d’apprentissage automatique, et en particulier les réseaux neuronaux profonds (« Deep Learning »). Ces réseaux ont, dans une première étape, été entraînés à évaluer des positions du jeu Go à partir d’un catalogue d’un million de parties jouées par des humains. Ceci a permis à Google AlphaGo de gagner contre des champions du monde humains. Puis, une nouvelle version appelée AlphaZero a supprimé cette contrainte, et a appris à évaluer la position en jouant des milliers de parties contre elle-même. Le processus peut être considéré comme darwiniste : après chaque jeu, quelques changements sont introduits dans la version qui a gagné pour produire d’autres versions, qui jouent les unes contre les autres, etc. Et juste en changeant les règles initiales, AlphaZero a appris en quelques heures à devenir aussi un grand maître aux échecs !
Aux niveaux inférieurs, il existe un mécanisme similaire appelé « apprentissage par renforcement » (Reinforcement learning). C’est l’une des méthodes clés à l’origine de l’explosion de l’IA que nous observons actuellement, utilisée notamment pour la traduction automatique, les assistants virtuels ou les véhicules autonomes. Le but est d’optimiser une séquence d’action pour atteindre un but de manière optimale (par exemple dans le jeu de Go, une séquence de placement de pierres pour maximiser l’encerclement du territoire adverse). Dans cet algorithme, un agent (c’est-à-dire un algorithme) sélectionne une action sur la base de ses expériences passées. Il reçoit une récompense numérique qui mesure le succès de son résultat, et cherche à apprendre à sélectionner les actions qui maximisent cette récompense. Au fil du temps, les agents apprennent ainsi comment atteindre un but. Pour améliorer le processus, un grand nombre de réseaux de neurones programmés au hasard peuvent être testés en parallèle. Les meilleurs sont sélectionnés et dupliqués avec de légères mutations aléatoires, et ainsi de suite pendant plusieurs générations. Cette approche est appelée « neuroévolutive » et basée sur des « algorithmes génétiques », illustrant la similitude avec l’évolution biologique. La fonction qui mesure le progrès vers les objectifs peut aussi être remplacée par une mesure de nouveauté, qui récompense un comportement différent de celui des individus précédents. Les chercheurs qui travaillent sur ces techniques d’IA, comme Ken Stanley, sont explicitement inspirés par la propension naturelle de l’évolution naturelle à découvrir perpétuellement la nouveauté.
3 – Le darwinisme et la numérisation des algorithmes humains
On discute beaucoup des impacts de l’IA sur les activités humaines, et il y a un consensus sur le fait que les robots et les agents virtuels, alimentés par des algorithmes d’IA, pourraient remplacer les humains dans de nombreuses activités. Or, ces activités sont permises par nos capacités cognitives, qui sont la conséquence de centaines de milliers d’années d’évolution darwinienne. On peut donc considérer qu’il y a une certaine équivalence entre les algorithmes et ces fonctions cognitives, et que celles-ci peuvent être considérées comme des algorithmes biochimiques. Par exemple, des algorithmes numériques comme ceux de la vision par ordinateur sont comparables, et potentiellement interchangeables, avec des fonctions codées dans les gènes. Cette analogie a amené l’expert en robotique Gill Pratt à poser la question suivante : » Est-ce qu’une explosion cambrienne est imminente pour la robotique?« , parce que l’invention de la vision au Cambrien a été la clé de voûte de l’explosion des formes de vie, et que quelque chose de semblable pourrait se passer si la vision est donnée aux ordinateurs. Les machines pourraient par exemple apprendre comment le monde physique fonctionne en « voyant » des milliers de vidéos, tout comme un bébé apprend la gravité et la conservation de l’inertie en observant le monde qui l’entoure. C’est actuellement un sujet de recherche actif pour les chercheurs en IA.
L’interchangeabilité des algorithmes entre l’humain et les machines est abordée par Yuval Noah Harari dans son best-seller « Homo Deus: Une brève histoire du futur« . L’un des concepts clés qu’il développe est que les organismes ont des algorithmes biochimiques pour « calculer » ce que l’on considère généralement comme des « sentiments » ou des « émotions », comme la meilleure décision à prendre pour éviter un prédateur, ou pour choisir un partenaire sexuel. Bien que ce ne soit pas explicitement mentionné dans le livre, ces algorithmes suivent un processus darwinien : ils se sont améliorés au cours de millions d’années d’évolution, et, si les sentiments de certains ancêtres ont conduit à une erreur, les gènes qui façonnent ces sentiments ne sont pas passés à la génération suivante. Harari soutient que les algorithmes numériques et les algorithmes biochimiques ont la même nature, et que les premiers sont susceptibles de devenir plus efficaces pour la plupart des tâches que les derniers.
Certains chercheurs, comme Richard Dawkins, considèrent également que les comportements ou les pratiques qui se propagent au sein d’une culture suivent des processus de Darwinisme universel. Les pratiques culinaires, les techniques agricoles, les croyances religieuses ou les stratégies guerrières sont des exemples typiques, mais les processus et le savoir-faire des entreprises entrent également dans cette catégorie. Le fait est que la plupart des mèmes sont des algorithmes : les recettes de cuisine sont de fait un exemple courant pour expliquer ce qu’est un algorithme. On peut donc considérer la transformation numérique des processus et des compétences dans les entreprises comme une transformation de la nature des algorithmes sous-jacents, depuis des algorithmes culturels vers des algorithmes numériques. Ceux-ci ont d’abord été développés par des informaticiens, qui ont codé explicitement des processus d’entreprises devenus de plus en plus automatisés. Mais ils sont maintenant complétés par l’apprentissage automatique, ce qui permet d’augmenter encore le niveau d’automatisation (par exemple en utilisant des algorithmes d’intelligence artificielle qui comprennent le langage naturel ou optimisent des activités complexes), ou d’améliorer les processus, en analysant le flux de données toujours croissant. Les entreprises n’ont d’autre choix que de s’adapter. Alors que le monde est de plus en plus bouleversé par les bouleversements numériques, la phase de Charles Darwin « ce n’est pas l’espèce la plus forte qui ne survit ni la plus intelligente ; c’est celle qui s’adapte le mieux au changement » est plus que jamais vraie.
Cette transformation numérique de l’entreprise conduit également à une compétition entre les humains et les machines, comme l’expliquent Erik Brynjolfsson et Andrew McAfee dans leur livre « Race Against The Machine« . C’est en effet une compétition darwiniste entre des formes d’algorithmes. Par exemple, les algorithmes basés sur l’apprentissage automatique d’Amazon sont en compétition avec ceux acquis par les libraires pour conseiller un client. Amazon développe aussi des systèmes basés sur l’IA pour le contrôler ses centres de données, gérer ses entrepôts et systèmes logistiques et automatiser les processus métier, ce qui leur permet de diminuer inexorablement l’intervention humaine. Quant aux algorithmes sous-jacents, ils sont continuellement améliorés par les développeurs, mais beaucoup ne sont même pas embauchés par Amazon grâce aux communautés Open Source. Les algorithmes sont également améliorés par de l’apprentissage automatique, en utilisant l’énorme quantité de données générées acquises par la plate-forme. Les humains peuvent difficilement rivaliser.
4 – Fermeture de la boucle et autocatalyse des algorithmes
Nous avons vu que les algorithmes numériques ont tendance à remplacer ou à compléter les algorithmes biochimiques et culturels (y compris les processus d’entreprise), et qu’il existe des boucles de rétroaction positives entre les deux cas. Mais d’autres boucles de rétroaction méritent d’être étudiées.
Par exemple, la diffusion des connaissances est accélérée par les technologies de l’information comme Internet, les smartphones, les cours en ligne, les moteurs de recherche, les assistants personnels, etc. Or ces technologies de l’information s’appuient sur de nombreux algorithmes numériques. Les algorithmes numériques accélèrent donc le rythme de diffusion des algorithmes culturels (par exemple, la formation en informatique), qui peuvent en retour accélérer le développement des algorithmes numériques.
Un autre exemple, assez différent, est le progrès récent dans la manipulation de l’ADN, tels que les techniques appelées CRSIPR/Cas9. Ces progrès sont la conséquence des avancées en algorithmique numérique pour séquencer l’ADN et déterminer sa fonction. Mais l’ADN est le support physique d’algorithmes pour créer des protéines. Par conséquent, les algorithmes numériques permettent la modification des algorithmes génétiques. Les répercussions pourraient être considérables dans l’avenir, car nous remplaçons l’ancienne évolution génétique, basée sur des mutations aléatoires, par des modifications ciblées du code génétique contrôlé par des algorithmes numériques. Ce n’est pas de la science-fiction : ces modifications ont déjà été appliquées sur des animaux, pour traiter certaines maladies. Cela donne un certain poids à l’opinion des transhumanistes, qui estiment que ces techniques pourraient, un jour, être aussi utilisées pour étendre les capacités biologiques des humains…
Le diagramme suivant illustre ces relations :
Nous l’avons vu, les plates-formes numériques permettent l’acquisition de données et l’exécution d’algorithmes. Elles réduisent la distance et les incompatibilités entre les données et les algorithmes, et, ce faisant, elles agissent comme des catalyseurs, permettant plus facilement d’appliquer des algorithmes aux données, et de créer des algorithmes à partir de données. Les algorithmes aident les développeurs à créer des algorithmes, et aident les spécialistes de l’apprentissage automatique à transformer les données en algorithmes. Les algorithmes ainsi créés sont ensuite utilisés dans les applications et les services hébergés par les plateformes, qui permettront à leur tour d’acquérir plus de données et gagner de l’argent pour investir dans de nouvelles versions, etc. Les plus grandes sociétés d’IA comme Google, Facebook ou Baidu se battent d’ailleurs pour créer des écosystèmes de développeurs qui pourront créer et développer de nouvelles idées d’algorithmes, de nouvelles variantes, les combiner, etc. C’est probablement la principale raison pour laquelle elles ont, par exemple, toutes mis en open-source leurs logiciels sophistiqués d’apprentissage profond (Deep Learning), afin d’amener les développeurs à utiliser leurs plateformes pour partager, modifier ou combiner du code, héberger les résultats, et augmenter ainsi la rétention des algorithmes dans leur écosystème.
Dans un proche avenir, ces plateformes dans le Cloud permettront aussi le partage des connaissances entre robots. Supposons par exemple qu’une voiture autonome rencontre une situation inhabituelle. Celle-ci pourra être envoyée vers la plateforme du fabricant, qui pourra l’utiliser pour re-entraîner les algorithmes de détection, et envoyer la nouvelle version vers tous les véhicules. Le processus pourra être largement automatisé, permettant des adaptations rapides aux changements de l’environnement.
Cette automatisation peut aller plus loin. Comme nous l’avons vu au sujet du jeu de Go, les progrès de l’apprentissage automatique autonome (« automated machine learning ») permettent aux algorithmes de créer de nouveaux algorithmes avec peu, ou pas, d’assistance humaine. Les réactions entre algorithmes dans les plates-formes qui les hébergent peuvent de ce fait être considérées comme autocatalytiques : ce sont des méta-algorithmes qui utilisent la proximité entre données et algorithmes au sein des plateformes pour créer de nouveaux algorithmes ou méta-algorithmes. Or selon certains scientifiques comme Stuart Kauffman, l’autocatalyse joue un rôle majeur dans l’origine de la vie, et plus généralement dans l’émergence de systèmes auto-organisés. Nous pensons que l’autocatalyse des algorithmes numériques est la percée majeure de l’IA, qui explique le mieux les progrès exponentiels que nous constatons.
Tous les pays industrialisés sont maintenant conscients de cette percée, et luttent pour développer et contrôler les algorithmes d’IA, car ils deviennent une partie essentielle de leur souveraineté et de leur indépendance. Le contrôle du processus d’innovation et des plates-formes deviennent d’une importance capitale. La Chine et les gouvernements américains, par exemple, en particulier les agences militaires et de renseignement comme le DARPA, investissent massivement dans la R&D autour du traitement des données et de l’intelligence artificielle, souvent en cofinancement avec les grands fournisseurs de plates-formes commerciales. En résulte un flux de nouvelles idées et d’algorithmes, qui sont sélectionnés d’une manière ou d’une autre. Celles qui apportent un avantage sont incorporées dans ces plateformes pour les usages commerciaux, mais peuvent également être utilisé par les Etats pour contrôler l’information et améliorer leur défense (comme les armes basées sur l’IA, les systèmes de renseignement…). Nous voyons ici clairement un processus de Darwinisme Universel.
En réaction, on voit émerger des initiatives comme OpenAI, financé par Elon Musk, dont le but est de « contrecarrer les grandes entreprises qui peuvent gagner trop de pouvoir en possédant des systèmes de super-intelligence consacrés aux profits, ainsi que les gouvernements qui peuvent utiliser l’IA pour prendre le pouvoir et même opprimer leurs citoyens ». Le premier projet est une plateforme open source pour aider à développer collaborativement des algorithmes d’apprentissage par renforcement, qui resteront libre de droits. Une telle plate-forme pourrait être un moyen d’éviter la rétention des algorithmes dans certains « organismes » comme les gouvernements et quelques grandes entreprises. Nous verrons si une telle initiative réussit, mais elle nous semble être une bonne illustration de la dynamique de l’évolution des algorithmes et ses conséquences que nous avons décrites.
5 – Conclusion
L’évolution des algorithmes est un sujet crucial pour comprendre l’évolution de notre civilisation. En regardant le passé, cette évolution peut à priori sembler imprévisible. Par exemple, personne, il y a 20, 10 ou même 5 ans, n’a été capable de prédire l’évolution des algorithmes d’IA ou la croissance de Facebook. Pourtant, cette évolution n’est pas aléatoire, car elle résulte de millions de décisions rationnelles, prises par une myriade d’acteurs comme les ingénieurs logiciels, les consommateurs, les entreprises et les agences gouvernementales.
Dans cet article, nous avons étudié l’idée que cette évolution a de fortes similitudes avec l’évolution biologique et culturelle, qui ont conduit à des ruptures telles que l’explosion cambrienne il y a 500 millions d’années, ou l’invention de l’agriculture il y a 12 000 ans. Notre thèse est que les mêmes principes du darwinisme universel s’appliquent, ce qui éclaire la manière dont les algorithmes évoluent au fil du temps, et ce dans des contextes aussi variés que le développement des logiciels dans les communautés open source, les plateformes numériques, la transformation numérique de notre société, les progrès de l’IA et l’impact de celle-ci sur notre société. Nous pourrions trouver d’autres cas qui cadrent bien avec ces principes, par exemple dans des domaines tels que la cybersécurité (comme la coévolution des logiciels malveillants et leur contre-mesure), l’apprentissage non supervisé (comme les très prometteurs Generative Adversarial Networks), ou l’optimisation des logiciels par l’introduction automatique de petites différences (« Automatic A/B Testing »).
Cette contribution ne prétend pas être un travail scientifique, ni conclure quoi que ce soit sur la pertinence du darwinisme dans d’autres contextes. Mais elle fournit un cadre explicatif de l’évolution des algorithmes indépendamment de leur support, qu’il soit génétique, culturel ou numérique. Nous sommes convaincus qu’il faut considérer les algorithmes de cette manière globale, pour comprendre la révolution numérique que nous vivons, déterminer quelles pourraient en être les prochaines étapes, et atténuer les risques pour nos démocraties. Pour aller plus loin, notre sentiment est qu’une théorie générale de l’évolution des algorithmes est nécessaire, qui soit bien intégrée dans des théories plus larges traitant de l’émergence de structures complexes dans la nature.
Cet article était une contribution à un livre sur “Gouverner la décroissance”, mais il n’a pas été retenu.
Il fait suite à un séminaire à l’Institut Momentum du 2/07/2016 sur “De l’accélération des algorithmes”.
Nous vivons une révolution en matière de « numérique », avec l’explosion des informations collectées et l’augmentation des capacités d’échange et de traitement algorithmique de celles-ci, conduisant notamment à l’émergence de formes d’Intelligence Artificielle (IA). Certains veulent croire que cette révolution apportera de la croissance, plus de démocratie ou plus de bonheur, tandis que d’autres craignent pour les libertés individuelles et les emplois, ou doutent de la pérennité d’une société hyper-technologique du fait de la déplétion des ressources naturelles. Dans cet article, nous soutenons l’hypothèse qu’effondrement sociétal et algorithmes sont liés par la thermodynamique, et qu’une nouvelle forme de darwinisme est à l’œuvre dans l’évolution des sociétés. Une telle hypothèse concilie différentes tendances que nous pouvons observer : augmentation des inégalités, accélération du progrès technique, concentration des données, signes d’effondrement. Elle nous amène à proposer des mesures pour augmenter la résilience de nos sociétés.
Information et résilience
Nous allons aborder dans un premier temps le lien entre information et résilience. Partons pour cela du concept de ‘gène égoïste’ de Richard Dawkins. Le gène est le support de l’information du vivant, qui permet à une cellule de synthétiser des protéines pour capter les flux énergétiques (par la photosynthèse et l’alimentation), transformer l’énergie en travail, constituer des organes, et se reproduire. Ce dernier point le rend résilient vis-à-vis de la disparition de l’organisme, et ce sur de longues durées. Dans le même ordre d’idée, Dawkins a introduit la notion de “mèmes”, qui sont des unités d’information enregistrés dans le cerveau, et qui se reproduisent par le langage et le mimétisme. Selon cette théorie, les mots, les traits culturels, les pratiques, les savoir-faire, les conventions, les symboles, etc sont des mèmes, qui se répliquent au sein d’un milieu social, et évoluent. Gène et mèmes suivent un processus de darwinisme généralisé, qui a 3 composantes: 1/ création de variantes, typiquement par mutation, recombinaison ou hybridation 2/ sélection des variantes les plus adaptées pour se reproduire et donc les plus stables 3/ transmission des caractères à des descendants. Ce faisant, il y a accumulation de l’information le long de lignées, et émergence de formes d’organisation. Les gènes permettent l’auto-organisation des organismes, les “mèmes” permettent l’organisation de sociétés humaines, formées d’individus partageant des connaissances et croyances identiques. Les sociétés humaines toutefois évoluent bien plus vite que les gènes, grâce au langage. Il y a eu en particulier une accélération avec l’invention de l’écriture, puis de l’imprimerie. Les nouvelles technologies de l’information démultiplient cette capacité de mémorisation de l’information, et la vitesse du changement.
Robots et startups
Pour se rendre compte de ce changement, considérons les robots humanoïdes tels que ceux fabriqués par Boston Dynamics. Il a fallu un million d’années d’évolution génétique pour que l’homme acquière la bipédie, mais il n’a fallu que quelques décennies après l’invention du transistor pour que des robots sachent marcher sur des galets, monter des escaliers, etc. D’autres robots, déjà, analysent mieux une image médicale qu’un médecin formé pendant des années, ou bientôt feront mieux qu’une armée d’avocats pour parcourir des jurisprudences, mieux qu’un chauffeur de taxi pour déplacer des passagers, etc. Le robot et l’écosystème technique qui le supporte (ingénieurs, constructeurs, société high-tech, finance …) mémorisent l’information bien plus vite que n’importe quelle structure de l’univers, et évoluent plus vite.
Cette “intelligence” des robots vient de dizaines de milliers d’algorithmes intriqués et combinés entre eux, et implémentés sous forme de code informatique. Un algorithme définit une séquence d’opérations, qui peuvent être simples comme trier des nombres, ou plus compliquées comme reconnaître des paroles et des images, planifier des actions ou répondre à des questions. Les gènes peuvent aussi être considérés comme des algorithmes, qui permettent la fabrication pas-à-pas de protéines et d’organismes selon un programme codé dans l’ADN. Les mèmes associés aux procédés, qui se transmettent au sein d’une culture donnée, comme les recettes de cuisine, les techniques de chasse ou les pratiques agricoles, peuvent aussi être considérés comme des algorithmes.
Gènes, mèmes et code informatique sont des supports de l’information dont l’action se renforce mutuellement. Les récents progrès en matière d’ingénierie cellulaire illustrent ce point: l’accumulation de connaissances mémétiques et le progrès des algorithmes informatiques permettent de comprendre le fonctionnement du code ADN, et de le reprogrammer par des techniques comme celle dite CRISPR-Cas9. Ces techniques de modification de l’information génétique ouvrent, par exemple, la possibilité de développer de nouvelles espèces de plantes, bien plus vite que ne peut le faire la sélection naturelle.
L’évolution des algorithmes suit un processus darwinien. Ils sont essentiellement développés par des programmeurs, puis sans cesse recombinés, utilisés dans d’autres contextes, et améliorés dans des versions successives. Les programmeurs partagent certains de leurs algorithmes au travers de communautés dites “open source” (comme celle développant le système d’exploitation Linux), ce qui accélère ce processus. Ils peuvent être embauchés par des startups, qui vont agréger des milliers d’algorithmes pour construire des produits. Ces startups sont en compétition entre elles, et les plus performantes sont acquises par de plus grosses entreprises. Celles-ci s’efforcent de contrôler certains algorithmes clefs, mais en diffusent d’autres afin d’entretenir ce mouvement darwinien de création et de sélection. Une société comme Google a ainsi pu accumuler plus de 2 milliards de lignes de code, ce qui est le même ordre de grandeur que le nombre de paires de bases dans l’ADN d’un humain. Cette accumulation lui permet de fabriquer des systèmes de plus en plus “intelligents”, à un rythme de plus en plus rapide.
Le processus s’accélère encore avec l’explosion des techniques d’apprentissage automatique, qui créent de nouveaux algorithmes à partir de grands volumes de données. Elles sont au cœur de l’IA (Intelligence Artificielle), et à l’origine de l’augmentation récente des capacités des robots ou des “assistants intelligents” évoquées précédemment.
Les sociétés thermo-numériques
En permettant une accumulation de l’information et une augmentation de la complexité, les mécanismes darwiniens semblent s’opposer à l’augmentation de l’entropie, pourtant inéluctable du fait du second principe de thermodynamique. En fait, comme, François Roddier l’a montré en reprenant les travaux d’Ilya Prigogine et d’Alfred Lotka, organismes et sociétés humaines sont ce que les physiciens appellent des structures dissipatives. Ces structures reçoivent un flux énergétique et maximisent la dissipation d’énergie et l’exportation d’entropie. Or on sait depuis Claude Shannon (1948), qu’entropie et information sont deux aspects opposés d’un même concept. En exportant de l’entropie, une structure dissipative importe et mémorise de l’information venant de son environnement. À l’intérieur de la structure se crée de la complexité et s’accumule l’information. À l’extérieur, il y a augmentation du désordre. C’est valable pour les cellules qui mémorisent l’information dans l’ADN, et pour les sociétés humaines qui la mémorisent via la transmission des mèmes. Notre hypothèse est que le même phénomène se produit avec les algorithmes.
Nous observons en effet une concentration des algorithmes. Alors que, techniquement, Internet pourrait être totalement distribué et sans contrôle, on voit émerger des plateformes comme Google, Amazon, Facebook, Microsoft ou Uber aux Etats-Unis, où comme Baidu et Alibaba en Chine, qui accaparent l’essentiel des requêtes. Ce faisant elles accumulent des données, et augmentent leur stock d’algorithmes par les procédés expliqués auparavant (open source, rachat de start-ups, IA, …). Certes la création d’algorithmes se fait dans le monde entier, mais ils s’accumulent dans certaines zones seulement où sont ces sociétés, comme autour de la Silicon Valley, Seattle et Boston aux USA, ou dans la région de Shenzhen en Chine. Ces zones ont les caractéristiques des cellules dissipatives: elles sont traversées de flux énergétiques, qu’elles dissipent en mémorisant de l’information. Nous appelons ces structures dissipatives des sociétés thermo-numériques. Elles ont une forte connexion avec une structure dissipative particulière, l’armée. Une armée en effet accumule le plus possible d’information, et a la capacité de détruire, donc de créer rapidement de l’entropie. Les armées, à commencer par la plus importante du monde, celle des États-Unis, investissent massivement dans les technologies de l’information pour construire des systèmes d’armes de plus en plus efficaces. Elles sont à l’origine de presque toutes les inventions de rupture, comme l’ordinateur, le transistor, Internet, le GPS ou les drones. Les armées cofinancent une bonne partie de la recherche fondamentale dans ce domaine, souvent en partenariat avec les grosses sociétés informatiques. Cette coopération contribue au darwinisme des algorithmes évoqués plus haut, puisque ceux ainsi créés peuvent rapidement se diffuser et participer au mouvement global d’amélioration du stock algorithmique, servant in fine à la fois la société thermo-numérique et son extension militaire.
Résilience des sociétés thermo-numériques
Nous avons donc deux phénomènes liés: d’une part, une consommation d’énergie et de matières premières, qui pourrait conduire à des déplétions et un effondrement global, et d’un autre côté l’accumulation d’information sous forme d’algorithmes dans certaines structures. La question qui nous intéresse est de savoir si ces structures peuvent perdurer après de fortes perturbations et réduction des flux de matière et d’énergie. En d’autres termes, les capacités d’adaptation qu’apportent aux sociétés thermo-numériques la capitalisation de l’information et la supériorité militaire leur permettront-elles d’être résilientes aux profonds changements à venir? Cette question est importante, car en dépend l’évolution des autres sociétés, et en particulier de la nôtre.
Nous pensons que la réponse est positive. L’évolution pourrait être comparable à celle de la vie sur terre, où des évènements externes ont provoqué des extinctions massives d’espèces (comme les dinosaures à la fin du Crétacé), mais pas celle de l’information génétique accumulée, ce qui a permis à des organismes ayant acquis des capacités d’adaptation ad hoc de prospérer dans le nouvel environnement.
Certes, le développement et la diffusion des algorithmes demandent actuellement des technologies numériques qui requièrent d’énormes dépenses énergétiques et de matière première. Ainsi, environ 10% de l’électricité mondiale est utilisée pour alimenter l’infrastructure Internet et la fabrication des équipements, qui demandent en outre de nombreux matériaux rares. Mais c’est en grande partie lié à une grande gabegie que permet encore notre monde actuel, avec un très fort effet rebond (on stocke des millions de vidéos de chatons ou d’anniversaire) et un renouvellement rapide du matériel. Il y a là un fort potentiel de réduction des consommations, en limitant les usages et augmentant la durabilité des équipements. Par ailleurs, il y aura encore du progrès technique, et il devrait être possible de transporter, stocker et traiter encore plus d’information avec beaucoup moins d’énergie. On peut également penser que la création automatique d’algorithmes pourra continuer même si les flux d’information décroissent, en se basant essentiellement sur l’énorme quantité de données déjà collectées, et avec des infrastructures réduites.
Enfin, et c’est peut être l’argument le plus important, les avantages compétitifs que procurent les technologies de l’information sont tels que les gouvernements qui les maîtrisent continueront très probablement à les soutenir quand les tensions augmenteront. Certes, les très fortes récessions à venir et les conséquences du réchauffement climatique mettront à mal les modèles économiques des actuels bénéficiaires de ces technologies, basés essentiellement sur la publicité et la consommation, mais la connaissance algorithmique accumulée restera disponible pour les systèmes sécuritaires et militaires..
La résilience des sociétés thermo-numériques pourrait aussi être mise à mal par les conséquences sociétales que provoqueront les destructions d’emplois consécutives à la multiplication de robots et d’assistants intelligents de toutes sortes. Mais pour le moment, force est de constater que les citoyens et hommes politiques se satisfont du changement de société que nous vivons. La plupart des partis politiques sont favorables à une plus grande dématérialisation de l’économie et de la vie en société, et votent des lois dans ce sens en espérant que cela conduira à un nouveau type de croissance. Même les partis anti-capitalistes semblent approuver cette économie numérique, alors que les mécanismes d’accumulation des algorithmes que nous avons décrits renforcent de facto le capitalisme. Quant aux citoyens, ils utilisent les innombrables services numériques, sans se préoccuper outre mesure des conséquences pour l’emploi, ou l’environnement. Peut-on imaginer un nouveau mouvement des canuts ou des luddites où les salariés se révolteraient contre les machines? Certes, ponctuellement, des catégories professionnelles protesteront et arriveront à bloquer quelque temps leur remplacement par des robots, mais nous voyons mal comment un tel mouvement se généraliserait. Le numérique conduit à une baisse du pouvoir des salariés par rapport aux propriétaires des algorithmes.
Les sociétés thermo-numériques, de plus en plus complexes et dépendantes des ordinateurs, pourraient aussi être victimes de cyberattaques massives, capables de bloquer les infrastructures et accélérer leur effondrement. Mais une telle attaque demanderait des besoins extrêmement sophistiqués, que seul un état peut mobiliser, et ne peut se faire que dans le cadre d’une guerre, ce qui est envisageable. Elles seront aussi victimes de mafias, qu’on pourrait qualifier de sociétés thermo-numériques car à la pointe de la technologie et munies de moyens importants de collecte de données, mais qui ne cherchent pas à détruire une société. Quoiqu’il en soit, le point à noter est que, pour détecter et contrer des virus informatiques bardés d’algorithmes, les sociétés développent d’autres algorithmes, toujours plus sophistiqués. On est dans une situation très proche d’organismes avec leurs systèmes immunitaires, qui sélectionnent et mémorisent des séquences d’ADN pour détecter et contrer des virus biologiques, et augmentent ce faisant leur résilience. Nous émettons l’hypothèse qu’il en est de même pour les sociétés thermo-numériques, qui sont globalement renforcées par les cyberattaques et, plus généralement, par tout ce qui stimule la sélection et l’accumulation des algorithmes. C’est un schéma proche de ce que Nassim Nicholas Taleb appelle l’anti-fragilité, où l’adaptation continue à des menaces augmente la résilience d’un système. L’exemple typique d’une telle adaptation est l’aviation, où l’analyse des accidents conduit à rajouter des mécanismes de sécurité qui complexifient les avions, ce qui se traduit par une augmentation globale de leur fiabilité. Plus généralement, l’accumulation d’information peut augmenter la résilience d’un système (une cellule, un avion, une société, …), avec une augmentation de la complexité.
Pour conclure cette liste d’arguments, rappelons aussi que les technologies de l’information permettent une modification du patrimoine génétique des organismes, bien plus rapidement que les mécanismes de sélection naturelle ou agricole, et donc plus à même à s’adapter aux rapides changements provoqués par le réchauffement climatique. Les perspectives sont vertigineuses, et inquiétantes, par exemple pour fabriquer des plantes adaptées à une baisse des ressources hydriques et des engrais, ou pour se défendre des maladies. Les sociétés qui les maitriseraient pourraient ainsi mieux résister aux famines et épidémies dont seront probablement victimes une grande partie des habitants de notre planète. D’autres pourraient créer des virus sélectionnant leur cibles… Ces perspectives sortent toutefois du cadre de cette étude.
Quelles Institutions de la décroissance
Nous avons esquissé dans les chapitres précédents les principaux arguments qui nous font penser que, dans certains endroits de la planète, des groupes humains continueront à développer les technologies de l’information et de l’Intelligence Artificielle. Ils pourraient ainsi être capables de maintenir une relative prospérité et les acquis du progrès. Cette prospérité ne sera pas partagée équitablement, car ces technologies, notamment les déclinaisons militaires, leur permettront d’accaparer les ressources dont elles ont besoin, au détriment d’autres sociétés qui, elles, s’effondreront au travers de guerres, régimes autoritaires et famines.
Nous ne voyons pas ce qui pourrait arrêter un tel mouvement, du moins dans les décennies à venir. On peut le regretter, mais nous préférons étudier comment ces technologies numériques, dans la mesure où elles seront disponibles, pourraient être utilisées à bon escient par les sociétés auxquelles la décroissance sera imposée.
Nous prendrons comme point de départ une des solutions les mieux adaptées pour faire face à la réduction des quantités tud’énergie disponibles: les systèmes de rationnement. Bien conçus, ils permettent d’organiser le partage d’une ressource de telle sorte que les inégalités ne se creusent pas, et d’assurer la résilience de la société face à une crise énergétique. C’est une solution qui a fait ses preuves dans le passé, par exemple pendant la dernière guerre mondiale, ou à Cuba durant la “période spéciale” qui a suivi l’effondrement de l’URSS.
Ces pays n’ont certes pas eu besoin de technologies de l’information pour mettre en place des tickets de rationnement, mais celles-ci peuvent grandement aider. Par exemple, dans le monde actuel où une grande partie des échanges monétaires se font via des moyens de paiement non matérialisés comme les cartes bancaires, il suffirait d’interdire tout paiement en liquide, et de mettre en place un décompte centralisé de tous les biens achetés par les particuliers et les entreprises. Les algorithmes dits de “Big Data” d’analyse de grandes quantités de données détecteront les tricheurs et éviteront le marché noir, en analysant finement toutes les transactions. Il serait assez facile également de mettre en place des monnaies électroniques complémentaires, afin d’augmenter la résilience du système financier local face à un krach financier. À partir de toutes les informations existantes, des modèles prédictifs pourront anticiper la production, et allouer au mieux les produits aux citoyens en fonction de la production et des besoins. Des systèmes similaires adapteront de manière optimale la production et la consommation de l’énergie, en pilotant le stockage local dans des batteries ou des chauffe-eau et l’adaptation de la demande en fonction de l’équilibre du réseau. Il sera possible avec ces solutions d’augmenter la part d’énergie renouvelable et décentralisée, donc la résilience à la pénurie d’énergies fossiles. Des vehicules électriques, éventuellement sans chauffeur, et dont la taille et les parcours seront optimisés par des algorithmes adresseront les problèmes de mobilité de manière bien plus efficace énergétiquement que les bus et les voitures individuelles actuelles, même partagées.
Par ailleurs, la vie dans une société post-pétrole demande la réappropriation rapide et massive de savoir-faire perdus et l’acquisition de nouvelles connaissances. Là encore, les technologies de l’information peuvent aider, via des cours en ligne dont les contenus faciliteront la transmission de savoir, par exemple pour produire localement de l’alimentation ou des biens, réparer les objets, se passer des engins agricoles, etc. Ils accéléreront aussi la formation aux nouveaux métiers. Plus généralement, les médias hautement interactifs et au contenu adapté à chaque audience aideront à la prise de conscience des citoyens sur la nécessité de changer de société. Mieux informés, ceux-ci pourront plus facilement participer aux débats et prises de décisions, grâce au vote électronique et la transparence des données. Une véritable société écologiste peut se mettre en place.
Mais un autre scénario est possible, proche de celui-ci, mais avec une conclusion différente, celle d’une dictature telle que décrite par Orwell dans “1984”. Le risque est en effet fort que, en cas de décroissance subie, des régimes totalitaires se mettent en place, et utilisent les mêmes technologies du numérique citées précédemment pour mettre au pas la société et forcer son adaptation à un monde post-croissance, au travers de la surveillance de masse, le contrôle de l’information, la propagande, des robots de maintien de l’ordre, etc. Pour un tel régime, le rapport coût-bénéfice de telles technologies peut être très important, car elles permettent à peu de personnes de diriger des masses d’individus pour un coût énergétique et matière relativement réduit. Les sociétés thermo-numériques qui maîtrisent ces technologies auront tout intérêt à autoriser cet usage, du moins ponctuellement pour assurer leur propre approvisionnement en ressources.
Pour éviter ce scénario, il faut organiser la décroissance, notamment au travers d’institutions destinées à faire face cette double rupture que constitue la fin de l’énergie abondante et la multiplication des algorithmes. Le chantier est immense. Concernant la partie ‘numérique”, il consiste pour l’essentiel à maîtriser autant que possible les algorithmes, avec l’assentiment des citoyens, et dans le but premier de réduire les consommations énergétiques.
Cette maîtrise a pour préalable la prise de conscience des mécanismes darwiniens décrits précédemment, et leur utilisation à bon escient. Ainsi, nous l’avons vu, la capitalisation des algorithmes passe par une phase préalable de dissémination. Des milliers de ‘hackers’ du monde entier savent capter ces algorithmes, les utiliser, les améliorer et les intégrer dans des produits. Il serait possible, pour une institution de la décroissance, d’utiliser et d’organiser cette connaissance et ces algorithmes pour créer des monnaies locales, des formations, des systèmes de quotas énergétiques, etc. En ce sens il faut encourager les mouvements de hackers, en particulier quand ils sont organisés pour satisfaire un but politique et réduire le pouvoir des sociétés géantes de la Silicon Valley, comme le Chaos club en Allemagne ou Framasoft en France. Leur action vise aussi à minimiser l’accumulation de données par ces sociétés, ce qui est une très bonne chose. Il faut développer les projets de réseaux Internet locaux et associatifs, basé par exemple sur des communications WiFi longue distance, qui permettent de se passer d’infrastructures lourdes et de maîtriser les flux. Un exemple de tel réseau est Guifi.net, en Catalogne, qui relie 30 000 nœuds dans une région peu dense. Au niveau étatique, les algorithmes devraient être considérés comme des biens communs. Des structures de recherche publique devraient être mises en place pour développer les applications de l’IA utiles pour la société.
Par ailleurs, il faut minimiser autant que possible la consommation énergétique et de matières premières d’Internet et des équipements. Beaucoup de pistes sont possibles. On pourrait par exemple limiter l’usage de réseaux sans fil pour diffuser de la vidéo, ou construire des téléphones et ordinateurs facilement réparables. Il pourrait y avoir un ralentissement du renouvellement des équipements, et une standardisation accrue, comme on peut le voir par exemple avec des calculateurs de type Arduino, dont les plans sont en “open source” et qui peuvent servir de base à de nombreux équipements numériques. De manière générale, les institutions de la décroissance devraient pouvoir limiter l’effet rebond et l’obsolescence programmée, et faire en sorte que les progrès techniques, et en particulier l’amélioration et l’intégration croissante d’algorithmes, servent vraiment à réduire les consommations énergétiques.
Conclusion
Nous avons fait un parallèle entre l’évolution des algorithmes accumulés par un groupe humain et celui des gènes dans un organisme. Nous avons montré que les processus darwiniens de sélection étaient comparables, et pouvaient conduire à une augmentation de la résilience de ces groupes, grâce notamment à une meilleure adaptabilité et une supériorité militaire permettant l’accaparement des ressources physiques.
Si cette théorie est juste, alors les technologies numériques continueront d’être améliorées, même dans un monde globalement, mais très inégalement, en décroissance énergétique, économique et démographique. Nous concilions ainsi plusieurs visions de l’avenir, entre ceux qui estiment inéluctable une baisse de la croissance et un effondrement de nos civilisations lié à un dépassement des limites physiques de la planète, et les optimistes qui estiment que le progrès technologique permettra d’autres formes de prospérité. Ces deux visions ne sont pas incompatibles.
Quels seront les contours de ce monde à venir? Verra-t-on une majorité de sociétés en situation d’effondrement et quelques îlots de prospérité, ou des choses plus complexes? Il ne nous est pas possible de répondre. Tout au plus pouvons-nous souhaiter que, dans des pays comme la France, il y ait à la fois une prise de conscience que les technologies ne permettront pas une augmentation importante du découplage entre activité économique et consommation énergétique, et également qu’elles peuvent faciliter la transition vers un monde en décroissance, et qu’on ne peut les ignorer. Cette prise de conscience devra conduire à des décisions démocratiques d’appropriation de ces technologies, assorties à une réorientation de leurs usages. C’est aussi tout l’avenir de nos sociétés industrielles qu’il faut repenser, face à cette double rupture que constitue la fin de l’énergie abondante et la multiplication des machines intelligentes.